15 How to add metadata to your data
15.1 JSON files
Each processed data file will be accompanied by a Javascript Object Notation (JSON) file that contains information about the content of the file. JSON files can be made in basic programs such as Notepad, but also Visual Studio Code, Jupyter Notebook, etc. When using Notepad just make sure to save your file under data types ‘all files’ and add the JSON file extension .json.
Tabular data
TSV files do not retain information regarding variable labels, values and value labels. Therefore, a JSON file will be created to ensure no information gets lost. This JSON file can then be used to facilitate analyses, by merging the variable information into the data.
Below you can find examples of what a JSON file could look like. You could also add information, such as task description, references, etc.
| Questionnaire | Behavioral task |
|---|---|
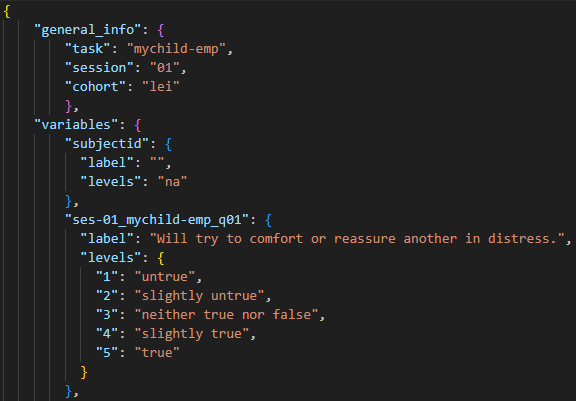 |
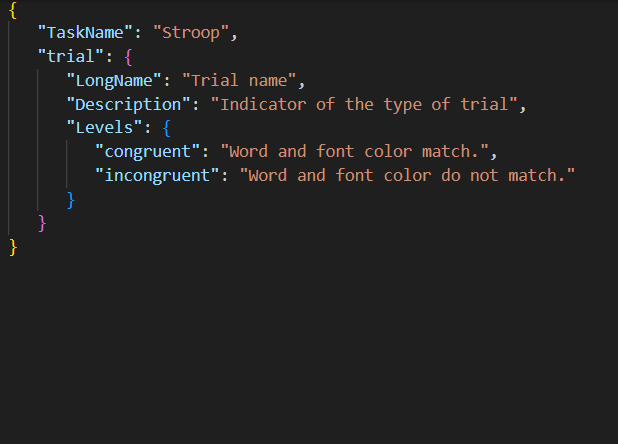 |
Automate json creation. Tabular doesn’t automatically get a JSON file. Therefore, we provide you with a script you can run to create basic json files (and .tsv files) from .sav files. Click here to download a beta version of the script.
If your data consists of non-sav (.csv/.xlsx/.tsv) files, you could still use the script but there won’t be any variable information in the JSON output as this is non-existent in the original file. You could also opt to convert the non .sav files to .sav files first and add variable and value information there and then run the script on the .sav files, or you could run the script on the non .sav files and add variable/value information to the output JSON file manually.
Non-tabular data
When bidsifying non-tabular data, such as (f)MRI/EEG files, JSON files should be automatically created. They contain information about echo time, slice timing, repetition time, (eeg) coordinates, and information about the scanner for example. In addition, you could manually add any other relevant information, such as task name or task description if not included in the output. There may also be information in the automatically created JSON file that isn’t crucial, you could opt to leave this out of the file.
| (f)MRI | EEG | Physiology |
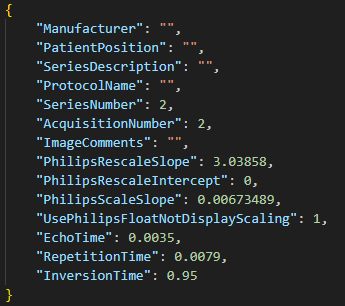 |
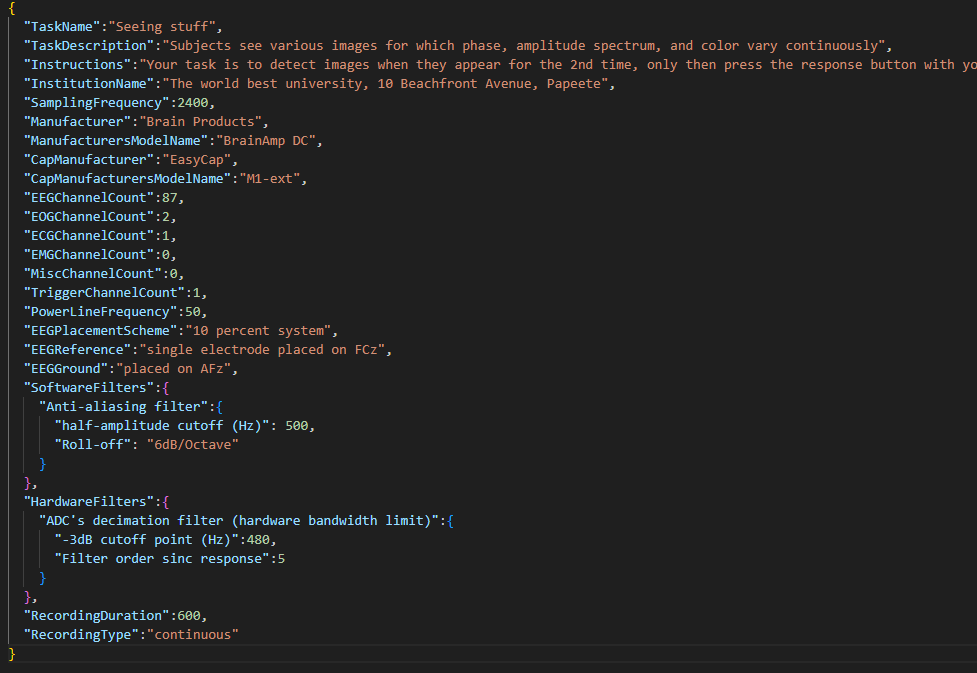 |
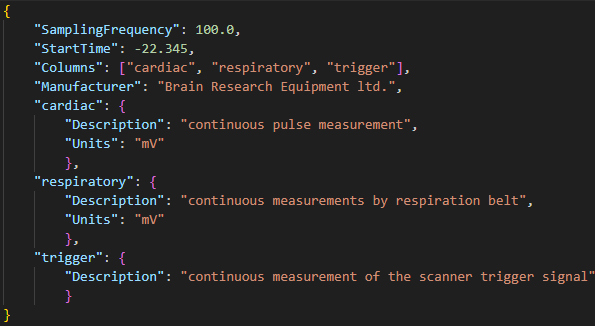 |
In addition to the information above, JSON files that accompany derivative data files need information about which file the derivative file originated from. Here primary data is the ‘guts-standard’ data which is located in the main subject folders.

15.2 Yoda metadata forms
Coming soon